Why can't TorToiSe be fine-tuned?
A surprisingly cunning move
TorToiSe :turtle: is an open-source Text-To-Speech (TTS) neural network that creates fairly authentic & realistic voices. Checkpoints for local inference have been available since April last year, but its users are seemingly unable to fine-tune the model with additional voice data.
Why is this the case, and how could it be fixed?
Preamble
First, let’s understand the situation.
The code, design, and training details for TorToiSe are well-documented. The main repo contains all of the code needed to download and run the TTS models (which are hosted on huggingface). The code for training TorToiSe from scratch is covered under the DL-Art-School project, and the overall process is well-documented in their draft paper.
With all of this available, it would be incredibly surprising if no one had successfully fine-tuned the model for their own purposes. As it turns out, someone has:
What I ended up doing instead was fine-tuning the TorToiSe models on several hundred hours of clips from the Lex Fridman podcast. I picked Lex’s podcast because it’s one of my favourites and he frequently talks about the concepts I want to explore with this project. His podcast was initially called “the Artificial Intelligence Podcast” which I also find very fitting.
I won’t go into the details of how I fine-tuned the model since there are some concerns with this being used maliciously. If you’re interested in fine-tuning your own model, to save you some time I will say that a critical component needed to do it has since been removed from the public release. So you won’t be able to do it without re-training some of the models needed from scratch.
A few searches on the GitHub repo later, and the ‘critical component’ is revealed:
This model is extremely potent when fine-tuned. It can be easily used to make deep-fake voiceovers of people. I’m sure you’ve heard the Joe Rogan and Steve Jobs podcast - that was Tortoise. Withholding the VQVAE which is required to perform that fine-tuning is my way of de-weaponizing it, to an extent.
– @neonbjb
Premise
The ‘critical component’ that has not been released is the “VQVAE” (or discrete-VAE), a model which (in this case) can encode/decode spectrograms into/from a list of integers (“MEL tokens”) in the range [0,8192).
The VQVAE is necessary for training, but also irrelevant for inference.
During training, the model is used to convert training data (the spectrograms of raw audio files) to discrete tokens that can be used by the GPT model (as predicted outputs) and the CLVP model (as inputs):
During inference, the MEL tokens are simply generated by the GPT model:
If none of that makes sense to you, well shit, I tried. I recommend reading the architectural design doc and the tortoise source code, especially api.py and models/autoregressive.py.
So, you need the VQVAE for fine-tuning. Okay, the code for it is here, the training hyperparameters are written here, and the dataset is…
I independently built an extended TTS dataset composed of audiobooks and podcasts scraped from the web. This data was split on 500ms silences, and any audio clip between 5-20 seconds was kept. I then fed the resulting clips through a pipeline of classifiers that I trained which remove any audio with background noise, music, poor quality (such as phone calls), multiple voices speaking at once and reverb. Due to disk space limitations, I was forced to limit the amount of scraping. The end result was 49,000 hours of cleaned audio clips.
I transcribed this dataset using a wav2vec2-large model. I personally fine-tuned this model to predict punctuation, as quotation marks, commas and exclamation marks are important for the purposes of generating speech but are not generally included in the training of speech recognition models. Fine-tuning was performed on LibriTTS and HiFiTTS and the pretrained model weights and transcription scripts can be found here.
…absent, but probably not too difficult to emulate with a combination of Whisper on LibriLight, plus some additional scraping of YouTube.
Is that it?
Problem
Unfortunately, this is not the end. Quoting from yet another issue:
If you are interested in the VQVAE model itself, I would be glad to divulge training details for it so you can build your own. It will not be compatible with the Tortoise codes, though (unless you are really lucky. :) )
To understand what this means, it is necessary to describe how the VQVAE works.
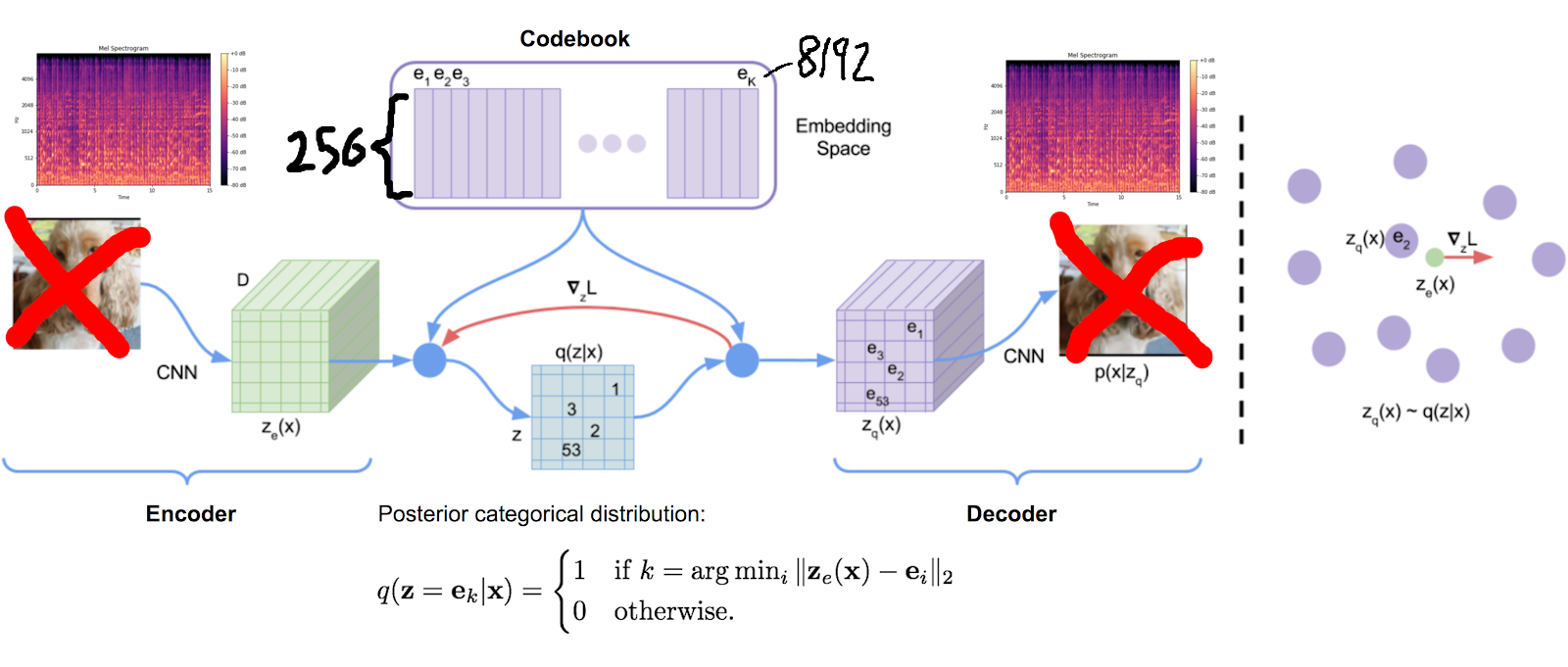
If you’d like a more accurate description with more detail, I recommend reading this blog.
But in simple terms:
- a codebook (list) of K arrays, each filled with
dimrandom floating point values, is created for the model - the encoder converts a spectrogram to a series of arrays of length
dim. for each array produced,- the codebook array with the closest euclidean distance is picked.
- the index of each codebook array picked corresponds to the MEL token
- the decoder converts the series of codebook arrays back into a spectrogram; the whole network is trained to minimise the reconstruction loss of that spectrogram
The codebook here is the problem. A fresh VQVAE, trained from scratch, would have a completely different codebook, and would fail to learn the same internal representations for audio.
Or, to be more concrete: if, given a short audio clip, the original VQVAE produces the MEL tokens [39, 3258, 1892, 8101], the new VQVAE is extremely likely to produce a completely different list of tokens, like [2814, 3250, 982, 5832], even if trained perfectly to negligible loss.
So, if you trained a fresh VQVAE from scratch, you would have to train the entirety of TorToiSe from scratch (ignoring the vocoder) as well to get it to work. Not ideal.
Surely there has to be some way to recreate the original VQVAE?
Proposal
When I quoted @lexman_ai above, he said:
So you won’t be able to do it without re-training some of the models needed from scratch.
Some of the models doesn’t sound like all of the models. Could it be possible to train a new VQVAE, while avoiding the problems I mentioned above?
Everything below this line is baseless speculation, so take it with a heap of salt
Formally, we can define the encoder/decoder pair of the VQVAE as functions $f(x) = z, g(z) = \hat x$, where
$$g(f(x)) \approx x$$
Informally, x is a mel spectrogram, z is a list of MEL tokens, and f is a 1D resnet.
Formally, our goal is to create a new encoder, $f’(x)$, such that
$$f’(x) \approx f(x)$$
for a varied distribution of values of $x$ and $z$.
Informally, you could generate a large dataset of synthetic [x,z] pairs by running inference on TorToiSe’s GPT model a lot of times, and train an encoder directly to try to predict z from x. You would have to replace the overall reconstruction loss function of the VQVAE with a different loss function (MSE?) that minimises the difference between the expected cookbook array vs the output array of the encoder, and also change up all of the training hyperparameters.
Would it work? I don’t know, but I can imagine a number of ways this could go wrong:
- The synthetic
[x,z]pairs are simply too low quality for a model to converge, - The specific random cookbook arrays used in the original VQVAE are important in some way that prevents a resnet with a different cookbook from learning to predict the right tokens
- i missed something obvious (it happens)
If I was really going to try this idea, I might do something like:
- using random lines + random conditioning latents from a large tts dataset, generate (with the GPT model) a low-quality unfiltered large dataset, plus a higher quality smaller dataset filtered with CLVP
- pre-train an encoder & decoder (separately) on the large dataset, before fine-tuning on the smaller dataset
- switch back to the original VQVAE training method with reconstruction loss, and fine-tune the entire VQVAE on librilight or some other dataset
- fine-tune the rest of tortoise to account for the differences between this reconstructed model && the original VQVAE
But it might not work. And if it doesn’t work, and it is truly impossible to fine-tune tortoise without training from scratch, then I can only congratulate the creator of TorToiSe for his ingenuity.