Non-determinism in GPT-4 is caused by Sparse MoE
What the title says
It’s well-known at this point that GPT-4/GPT-3.5-turbo is non-deterministic, even at temperature=0.0. This is an odd behavior if you’re used to dense decoder-only models, where temp=0 should imply greedy sampling which should imply full determinism, because the logits for the next token should be a pure function of the input sequence & the model weights.
When asked about this behaviour at the developer roundtables during OpenAI’s World Tour, the responses of the members of technical staff were something along the lines of,
Honestly, we’re confused as well. We think there might be some bug in our systems, or some non-determinism in optimized floating point calculations…
And internally, I was thinking – okay, I know the latter point is true sometimes, and maybe OpenAI doesn’t have enough engineers to look into a problem as small as this. I felt a little bit confused when I noticed a reference to this behavior over 2 years ago – 2 years, and this couldn’t be fixed?
But I didn’t have a meaningful alternative explanation for the phenomenon. After all, why would you want to keep things random? Ilya’s always going on about reliability, right? There was no way OpenAI wanted to keep determinism bugged, so an unresolvable hardware limitation was the best explanation.
3 months later, reading a paper while on board a boring flight home, I have my answer.
In the recent Soft MoE paper, there was an interesting blurb in Section 2.2 that sparked a connection:

Under capacity constraints, all Sparse MoE approaches route tokens in groups of a fixed size and enforce (or encourage) balance within the group. When groups contain tokens from different sequences or inputs, these tokens often compete against each other for available spots in expert buffers. As a consequence, the model is no longer deterministic at the sequence-level, but only at the batch-level, as some input sequences may affect the final prediction for other inputs
It is currently public knowledge that GPT-4 is a Mixture of Experts model. Given that GPT-4 was trained before Q2 2022, and that Sparse Mixture-of-Experts have existed long before that, I think the following hypothesis is justified:
The GPT-4 API is hosted with a backend that does batched inference. Although some of the randomness may be explained by other factors, the vast majority of non-determinism in the API is explainable by its Sparse MoE architecture failing to enforce per-sequence determinism.
This is either completely wrong, or something that was already obvious and well-known to people developing MoE models. How can we verify this?
Are you really sure it isn’t hardware?
Not yet. Let’s ask GPT-4 to write a script to test our hypothesis:
| |
This final script is a little different from what you’d see if you clicked on the share link. I had to redo the script a few times along the way, because of a few problems:
the OpenAI API was taking very long to respond. I had to add timestamp logging to check I wasn’t doing something wrong – I wasn’t, the API was simply really slow, with nearly 10 seconds of delay to call even 3.5 turbo. I wonder why?
some completion models were truncating their responses very early. I added a logit bias against EOS to try to fix this.
Related: there is no equivalent bias against the
<|im_end|>token; the API returns,Invalid key in 'logit_bias': 100265. Maximum value is 100257.100265 is the accurate value for<|im_end|>: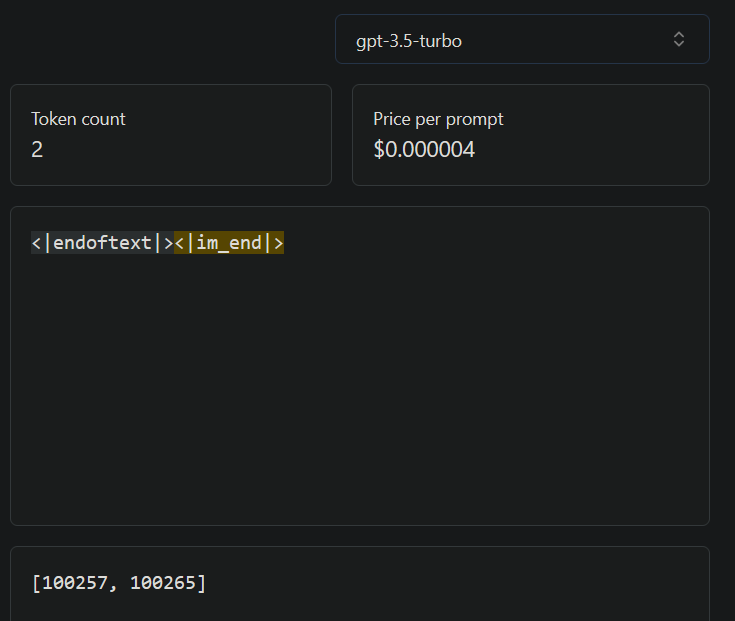
I figured this lack-of-logit-bias problem for the chat models was a non-issue – most completions reached the max token length, and they were absurdly more non-deterministic anyway (adding the logit bias would realistically only increase the number of unique sequences)
An hour of waiting and scripting later, and I got confirmation:
Empirical Results
Here are the results (3 attempts, N=30, max_tokens=128):
| Model Name | Unique Completions (/30) | Average (/30) | Notes |
|---|---|---|---|
| gpt-4 | 12,11,12 | 11.67 | |
| gpt-3.5-turbo | 4,4,3 | 3.67 | |
| text-davinci-003 | 3,2,4 | 3.00 | |
| text-davinci-001 | 2,2,2 | 2.00 | |
| davinci-instruct-beta | 1,1,1 | deterministic | Outputs deteriorated into repeated loop |
| davinci | 1,1,1 | deterministic | Outputs deteriorated into repeated loop |
Before I noticed the logit_bias problem, I also obtained the following results (max_tokens=256):
| Model Name | Unique Completions (/30) | Notes |
|---|---|---|
| gpt-4 | 30 | |
| gpt-3.5-turbo | 9 | |
| text-davinci-003 | 5 | |
| text-davinci-001 | 2 | Noticed the logit bias problem at this point |
Yes, I’m sure
The number of unique completions from GPT-4 is ridiculously high – practically always non-deterministic with longer outputs. This almost certainly confirms that something is up with GPT-4.
Additionally, all other models that do not collapse into a repetitive useless loop experience some degree of non-determinism as well. This lines up with the public claim that unreliable GPU calculations are responsible for some degree of randomness. However,
- I’m still partially confused by the gradual increase in randomness from text-davinci-001 up to gpt-3.5-turbo. I don’t have a neat explanation for why 003 is reliably more random than 001, or turbo more so than 003. Although I expect only the chat models to be MoE models, and not any of the 3.5 completion models, I don’t feel confident based on the current evidence available.
- This is only evidence that something is causing GPT-4 to be much, much more non-deterministic than other models. Maybe I’m still completely wrong about the MoE part. Maybe it’s just because of parameter count. (but then – why would Turbo be more unpredictable than davinci? Turbo’s faster; if you assumed the same architecture, Turbo ought to be smaller)
Implications
It’s actually pretty crazy to me, that this looks true. For a few reasons:
We’re so far behind
If the non-determinism is an inherent feature of batched inference with Sparse MoE, then this fact should be visibly obvious to anyone that works with models in that vein.
Given that the vast majority of GPT-4 users still have no idea what is causing their API calls to be unreliable, it should be concluded that (I am completely wrong, OR) too few people know anything about MoE models to launch this explanation into the public consciousness.
It implies that Google Deepmind knew, and found it trivial enough to write as a throwaway sentence in a paper. It implies that I should be a lot more bullish on them, and a lot more bearish against every other wannabe foundation model org that’s still working on dense models only.
GPT-3.5-Turbo may be MoE too
I heard a rumour, once, about 3.5-turbo sharing the same architecture as GPT-4; just with much much less parameters than it, or even GPT-3.
And, when I heard it, I was thinking: Nah, that sounds too complicated for a small public model. Why wouldn’t they just use a dense one? Fits on one GPU, no complexity overhead, really simple to optimise…
Fast forward to now, and we’re still suffering a regime where it takes 70B parameters to meet Turbo’s performance – a number which just doesn’t make sense for how much traffic OpenAI’s handling, and how much speed they get.
It’s also easy to notice that Turbo is the only other model in the API that has its logprobs restricted from public view. The common explanation was that they were restricted to prevent increased accuracy in distillation, something which sounds a little bit naive today given Orca and others. OpenAI has also publicly stated that they’re working on getting the logprobs integrated into ChatCompletions, making “prevent distillation” less likely than “this is hard to engineer reliably because they’re inherently too random right now”:

But, still, as I said earlier – not fully confident on this one. Maybe someone should open a prediction market?
Conclusion
- Everyone knows that OpenAI’s GPT models are non-deterministic at temperature=0
- It is typically attributed to non-deterministic CUDA optimised floating point op inaccuracies
- I present a different hypothesis: batched inference in sparse MoE models are the root cause of most non-determinism in the GPT-4 API. I explain why this is a neater hypothesis than the previous one.
- I empirically demonstrate that API calls to GPT-4 (and potentially some 3.5 models) are substantially more non-deterministic than other OpenAI models.
- I speculate that GPT-3.5-turbo may be MoE as well, due to speed + non-det + logprobs removal.