Here’s a thesis (hypothesis, predicate, etc) to chew on:
The mixture-of-experts paradigm is fundamentally a hinderance to open source development, and mixtral-8x5B+2B will be summarily supplanted by a dense model like llama3/mistral-70b/yi/qwen/… in the near future.
The case in favor of the take is pretty simple, involving points like,
most consumers being more vram limited than anything else
expectation that mistral’s capabilities are easily replicable via multi-epoch training
The rest of this article will be dedicated to finding counterarguments / surprise outcomes that may disrupt this narrative.
Fine-tuning difficulties
As of current writing, mixtral QLoRA experiments are showing fairly bad results, with people reporting odd behaviours on models or plainly seeing loss curves explode:
this is a placeholder image
This is the kind of thing you’d expect in advance for a variety of reasons – most of which are covered in papers like ST-MOE – including:
lack of auxiliary/balancing/z-loss. people who chuck in MixtralForCausalLM into normal dense model trainers will end up with no auxiliary loss – output_router_logits is disabled by default – much less additional stabilisers like router z-loss:
lack of MoE-training-specific hyperparameters like Capacity Factor, Expert Dropout, routing jitter, etc.
Batch sizes being too small. The HF MoE Blog notes that the ST-MOE paper recommends “small” batch sizes……but “small” in this case refers to a token batch size of 65k tokens (or a sequence batch size of ~128, since this is for T5 which has ctxlen==512). Most consumer LoRA runs do not have a batch size that large.
router being trained in half precision at all.
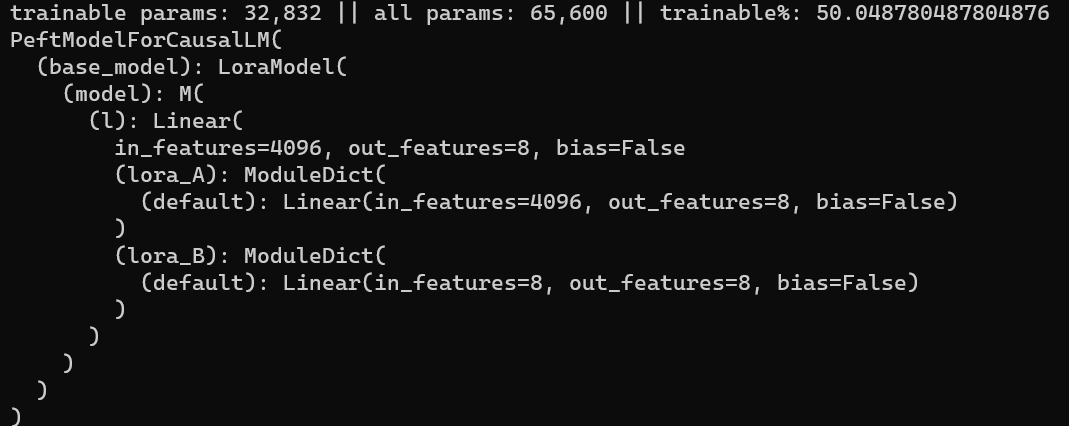
having a LoRA adapter over the routing layers at all. Each layers.[0..32].ffn.gate layer in mixtral is a Linear(dim,8); training it a LoRA with $r>=8$ creates an adapter bigger than the gate itself:I am not quite sure what the effect of this is yet, but I suspect it is not a good thing to be doing.
Most of these issues are engineering issues that can be solved with time.
Emphasis on can: it is always possible to make things work (“Neural networks want to work”), but attention in the open source community is fickle, and each failed training run strikes against the momentum of Mixtral’s release. It doesn’t help that mistral improved their alignment recipe for Mixtral-Instruct – having a decent baseline makes it all the more difficult for fine-tuning hobbyists to produce a cool release.
But…
Fine-tuning will become easier
Despite problems, mixtral is an inherently strong model, and consequently, there are a lot of people trying to make it work. I expect many, if not all of the above issues to be addressed within a week.
Additionally, many of the above tricks for MoE fine-tuning stability may prove themselves to be unnecessary over time.
Plausibly, QLoRA itself will act as some form of regularization / divergence penalty that helps to keep MoE fine-tuning more stable than it has been reported to be in the past.
There is a large space of dumb ideas that may “just work”, e.g. freezing the routers, or forcing expert randomization, or throwing compute at hparam search, or…
In general, having a learned bias against unreplicated academic papers that say “This is the way things should be done”.
The vRAM problem
There are many axes of comparison to flatter MoE models with. On steps-to-reach-loss, FLOPs-to-reach-benchmark, inference speed, etc, the mixture-of-experts paradigm gets anywhere between 2x~5x improvement over an appropriate dense baseline.
vram-to-loss is not one of those axes. Fundamentally, the mixture-of-experts paradigm is unfriendly to high FLOPs & low vRAM developers, a condition which adequately describes the vast majority of the open LLM community, operating on consumer hardware.
Given two models – a dense model with P parameters, and an MoE model with P total parameters – trained on the same dataset D, the dense model will always win 100% of the time. This is often misunderstood in mind-numbing directions (e.g. “MoE models train worse”), but for the purposes of an end user that receives a model checkpoint and is planning on running at batch size 1, the accusation of MoE being useless is difficult to shake.
But…
Does not apply for some users
Even if MoE models are a poor fit for most NVIDIA/AMD consumers, they are still generally useful for other local users; primarily CPU && Apple Silicon devs, e.g. It is currently possible to obtain ~60tok/s on an M2 Ultra on the llama.cpp fork for mixtral. In general, local MoE models are a good fit for people who have more RAM than they know what to do with, and who have too few FLOPs or memory bandwidth to utilize a dense model large enough to occupy their entire memory.
Also, some open source companies are big enough to afford datacenters. For those people, MoE models are a pareto improvement on memory bandwidth || FLOPs required for capabilities, and it’s an obvious benefit to be using them when decent integrations with e.g. vllm already exist.
Is currently not even true
It’s also currently not even the case that we have a dense model outperforming Mixtral while being the same size (or less) than it. None of the other open LLM releases in 2023 have matched up with Mistral’s sheer parameter efficiency, and it’s debatable whether we should expect any dense releases <=40B to beat Mixtral soon.
Personally, I expect the vast majority of Mistral’s capabilities to be the result of multi-epoch overtraining, which necessarily leads me to expect a dense baseline beating Mixtral soon. But this is an expectation that could be disproven with time.
Will be defeated soon
I find it reasonable to expect that MoE models will have a better “theoretical compressibility” than their dense counterparts. Sparse-but-undertrained models like switch-c-2048 or fairseq’s have been empirically demonstrated to be compressible to sub-1-bit precision, although it’s far less likely that an overtrained model like Mixtral will be equally compressible.
There are also ongoing efforts by the bitsandbytes developer, Tim Dettmers, to drastically sparsify MoE experts. And there are various hacky efforts by the OSS community at large to try to merge expert layers via existing techniques.
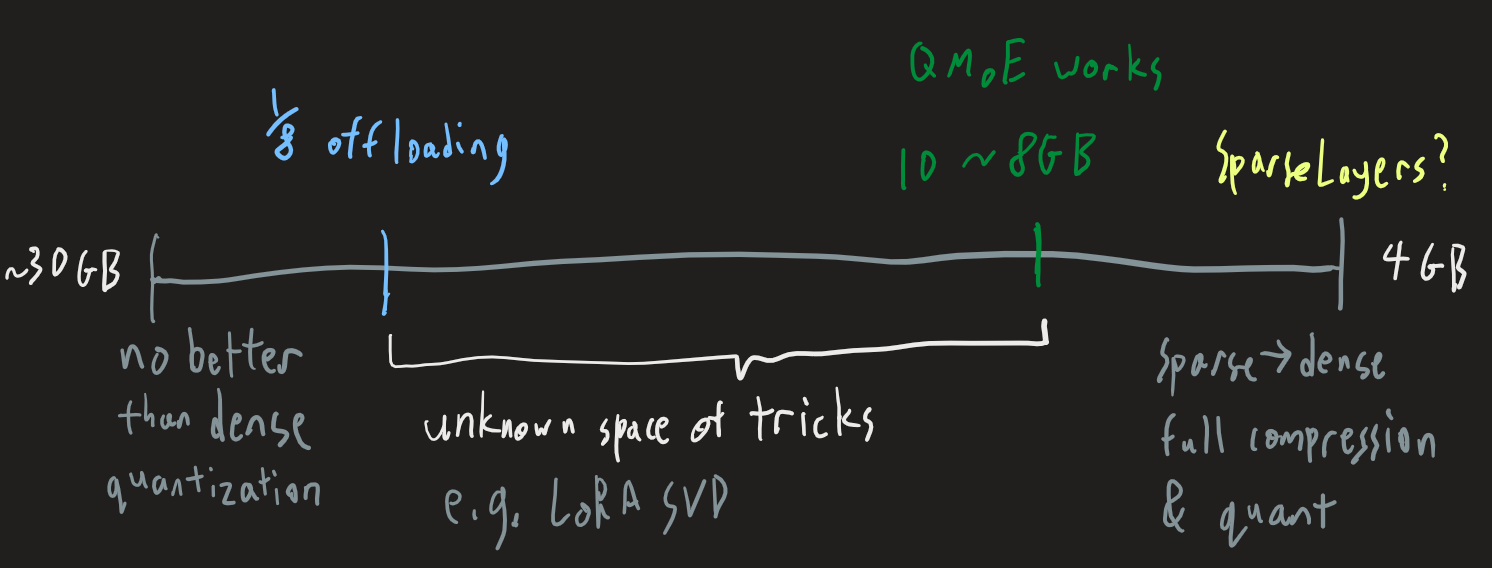
We can imagine some scale of compressibility – one that starts with “no better than dense 4bit quants”, and one that ends with “we perfectly merged this back into a 12B model”:
forgive the bad handwriting please
We will probably land somewhere in the white chunk of the line, and we will probably figure out some vram-saving hacks that come at a partial performance hit.
What will not work
Offloading
Complete offloading will not work. It may be possible to solve the latency of expert fetching via some experimental techniques, but the strong bottleneck is ultimately the expert throughput, aka your PCIe bandwidth.
On a standard 4x16 link, a GPU can request 32GB/s unidirectionally from CPU memory. Assuming nothing else on the system presents a greater bottleneck, that locks the user at 1/(2*size_of_layer_expert_in_GB) ~= 4 tokens per second. And this is the best you will ever get without resorting to non-standard inference strategies like some hypothetical dynamic top-k
Final note
This article is an artefact of its time – it is an attempt to describe the state of affairs as of 13th December 2023, with facts, claims, and predictions appropriate for the date. It is highly likely that many of the assumptions & beliefs described in this article will be invalidated by the end of the week.
I publicise this for the sole purpose of gathering my thoughts on the matter, as well as to potentially spark useful discussions on the topic.