In a previous blogpost, I made a simple observation about GPT-4 from a paper I had incidentally read on a whim. After finishing the post, I realised I didn’t actually ever figure out how token dropping could occur; only learning a black-box rule that it could occur in batched MoE inference for reasons.
This post is here to fix that – to collect enough info from important MoE papers (and alleged GPT-4 leaks) to explain the full mechanism of token dropping.
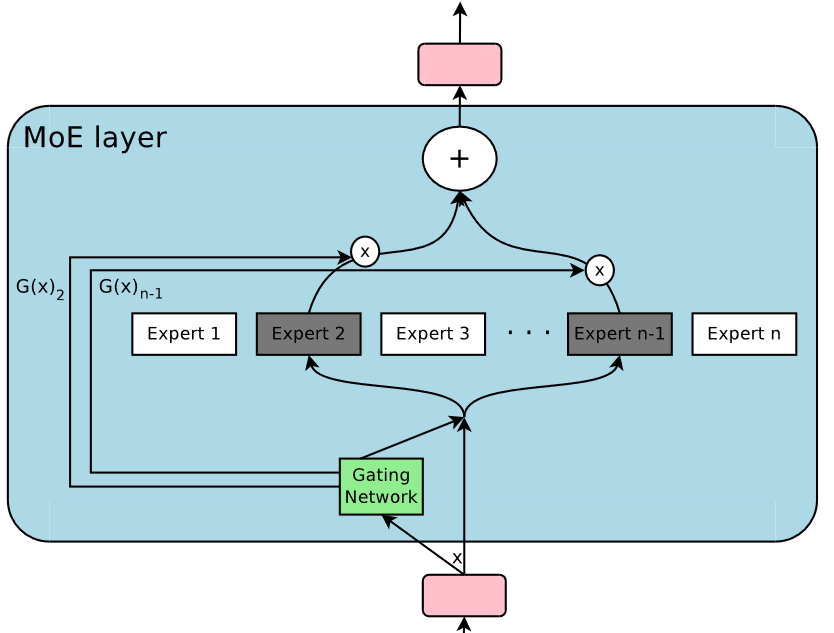
$n$ feed-forward networks as experts ${E_i}^n_{i=1}$
A trainable Router that can map each token to a number of experts.
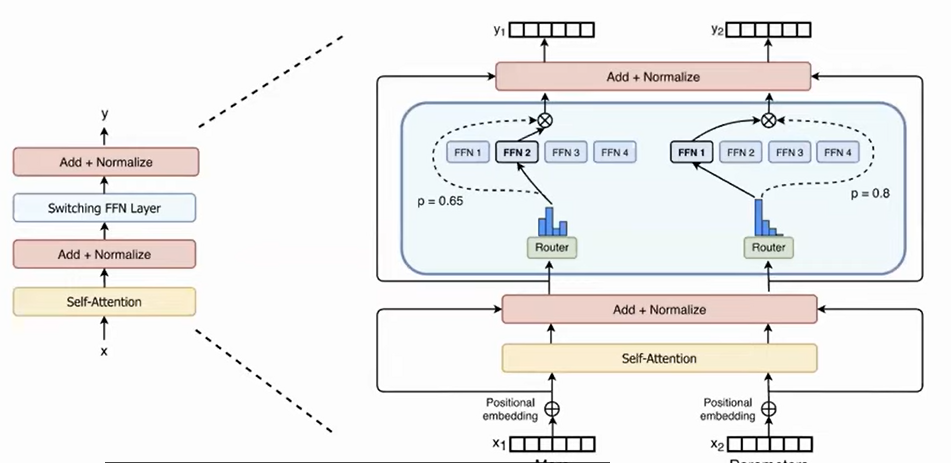
A Switch Transformer implementing a top-1 token choice router.
Don’t think of MoE as an ensemble/menagerie of domain experts; think of it as a novel approach for structured sparsity – the router gets to select some input tokens, directing each token to a fixed subset of all of the FFN weights.
There are a lot of extra details (differentiable load balancing loss, preventing representation collapse, extra tricks/hparams for training stability, etc) needed to make MoEs work at all, but for the purposes of this article, we only need to focus on one thing:
Routing strategies
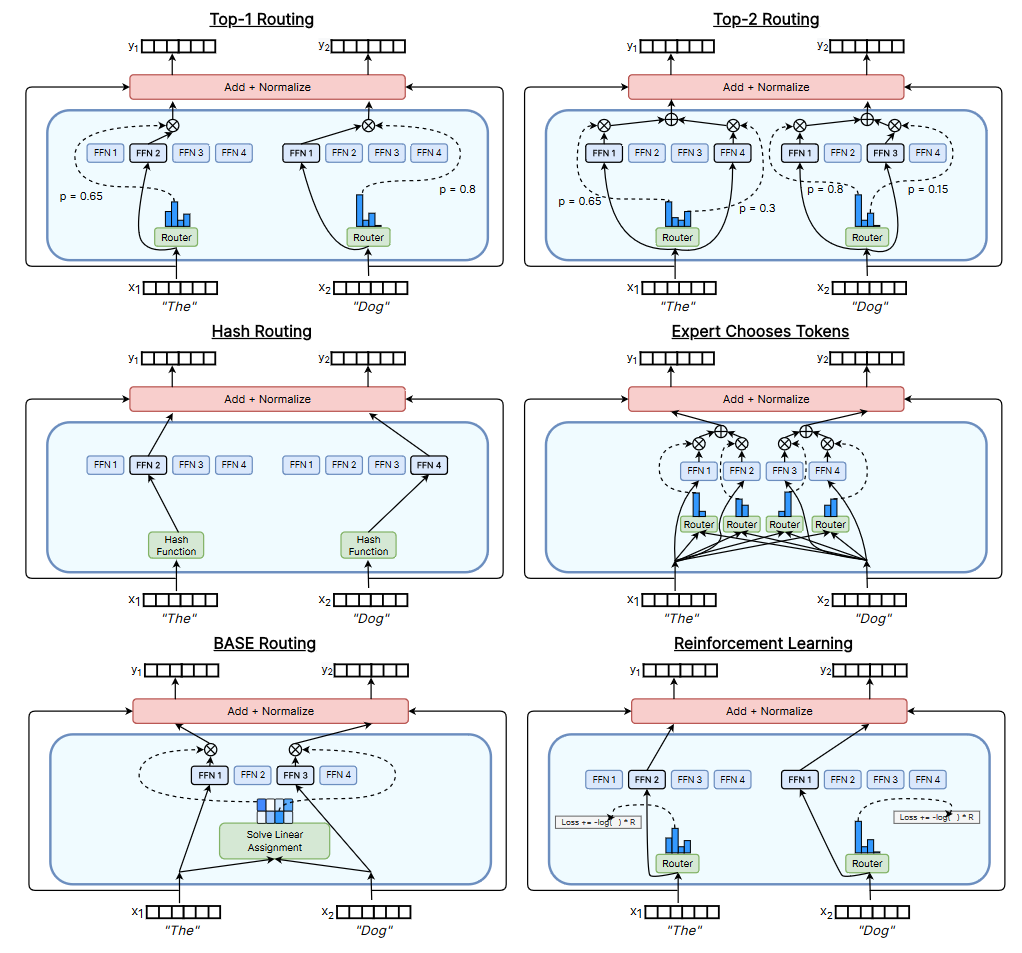
There are a few different routers that could’ve been used for GPT-4:
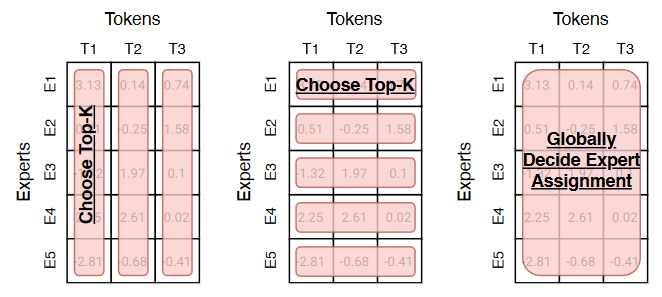
In Token Choice routers, the router learns a probability distribution over $n$ experts, so as to route each token to a few (typically $1<=k<=2$) selected experts.
In Expert Choice routers, the router selects the best k tokens for each expert.
We will ignore a number of other routing approaches, including:
In BASE Layers, token allocation is treated as a linear assignment problem – each expert gets a fixed number of tokens, and the optimal solution is something that doesn’t involve dropping any tokens.
Effectively random routing methods, where tokens are probably not going to be dropped because random selection balances out well enough that some extra capacity should prevent dropping most of the time.
For example, in Hash Routing, a hash function on the input token is used to decide what router it goes to. Similarly, THOR randomly selects 2 experts per token.
In Soft MoE routers, each token is assigned a per-slot dispatch weight, and each expert processes a few slots; no tokens are dropped under this paradigm either. I also find it unlikely OpenAI invented that (or any bespoke method) in-house 1.5 years ahead of time.
So, we can roughly whittle down the options available to two: Token Choice, or Expert Choice. Can we do better?
Unhelpful: cutoff dates for GPT-4
GPT-4 was released on 27 Mar 2023. They spent six months doing safety research prior to release, and allegedly took three months to train the base model. That implies that the latest date the architecture could have changed is around late June 2022, or basically any time period before 2022 Q3.
We also have a lower bound for the earliest date the GPT-4 architecture could’ve stopped changing. Certain core contributors to GPT-4 were still writing papers for DeepMind as late as Feb 2022. A substantialnumberof interesting papers were released in that time-period of early 2022, including (rather critically, for this article) Expert Choice. It’s not immediately obvious which one of the ideas made it into the final product, so we’ll have to dig deeper.
Helpful: GPT-4 leaks
Some information about GPT-4 has leaked to the public, over the months. I discuss the publicly known sources.
Geohot statement
In the famous geohot interview that lead to public hype about GPT-4’s status as a Mixture of Experts, he stated that GPT-4 did “16 inferences”, something which was confirmed by @soumithchintala.
‘16 inferences’? What?
So, how can you make a model with 8 experts do inference 16 times?
you could allocate each token to multiple ($N$) experts (okay)
you could repeat the forward pass a few ($M$) times (?)
and do that enough times that ($N * M = 16$) (???)
Do I find this unlikely? Not entirely; it would go a long way to explain why GPT-4 is so slow. But there are a lot of other things that are off here, like:
each “head” (attention head? expert model?) being 220B params each. that would never fit on a single H100, or even an NVL H100 pair without 4bit. Not to mention the insane batch sizes they’d be operating at, or what training would be like.
Geohot stating they’d spent “eight times the money” to get their model:This is not how MoE works.
So, let’s discard this event, and move on to the better source:
Semianalysis
In contrast, we can have a much, much better narrative of what GPT-4 looks like from the semianalysis article about it. To avoid being sued by Mr Patel, I will only include enough details to finish the main conclusions of this post. The relevant claims on GPT-4 are that,
it has ~55B shared params for attention. I assume that this means their attention layers are normal dense MQA stuff.
Each MLP expert is ~111B params. This matches up with what you’d expect for the MLP:attn ratio.
each forward pass takes ~280B params of a total of ~1.8T. 2 experts are routed to per forward pass.
OpenAI’s routing algorithms are “allegedly quite simple”. This is what I meant earlier, when I discarded RL routing as a possibility. Although maybe RL is simple for them? 🤔
Experts receive an uneven number of tokens. Note the quote:
“it could mean 1 expert could be at a batch size of 8 and others could be at 4 or 1 or 0.”
That last point is the most critical: it invalidates Expert Choice as an option, because in EC, every expert gets to pick K tokens (repeats are allowed).
Conclusion
GPT-4 uses a simple top-2 Token Choice router for MLP MoE layers. It does not use MoE for attention.
The process of token choice
The bulk of this section is simply a verbal reconvening of information obtained via the CS25 Lecture on Switch Transformers. I encourage you to watch it.
Now that we (roughly) know what routing strategy OpenAI is using internally, how can we explain the process of token dropping?
Picking a token
MLP layers take in a list of tokens (tensor of input embeds) as input. Each token hits a Gating network, $G(x)$, that returns a list of probabilities ($g_x$) for each token being picked by an expert.
In top-2 Token Choice, the top 2 highest probability experts are selected, and the end result is calculated as,
$$ y = G(x)_iMLP_i(x) + G(x)_jMLP_j(x)$$
Although the training process is supposed to spread the input tokens across the experts as evenly as plausible, it’s natural that certain inputs will cause some experts to be activated more than others (if not, why even have experts? shouldn’t some experts do better than others…?).
In extreme cases, the same two experts might simply get all tokens in the sequence – or in the batch, if batch size > 1. GPT-4 can accept 32K tokens; if all tokens in a batch of 32 were sent to the same expert, the effective token batch size on that single expert would be effectively >1million. In general, you could have $O(batchsize * tokens = BS_{tokens}$)$ inputs into one expert in one forward pass, if you’re not careful.
Wait, really?
I mean, is that really true? Can’t you just, delay the requests, do some dynamic initalization of experts (more copies of certain experts than others to combat imbalance), split apart batches, or any other hotfix?
The other way to think of this is in historical terms. A lot of the initial work on MoE transformers was done at Google, where they use(d) Tensorflow/JAX and TPUs. The XLA compiler needs a static size for all tensors, unlike Pytorch where you could theoretically just take the dynamic inputs on an infinite vram computer. Expert Capacity was thus introduced to make token choice work where static shapes are required.
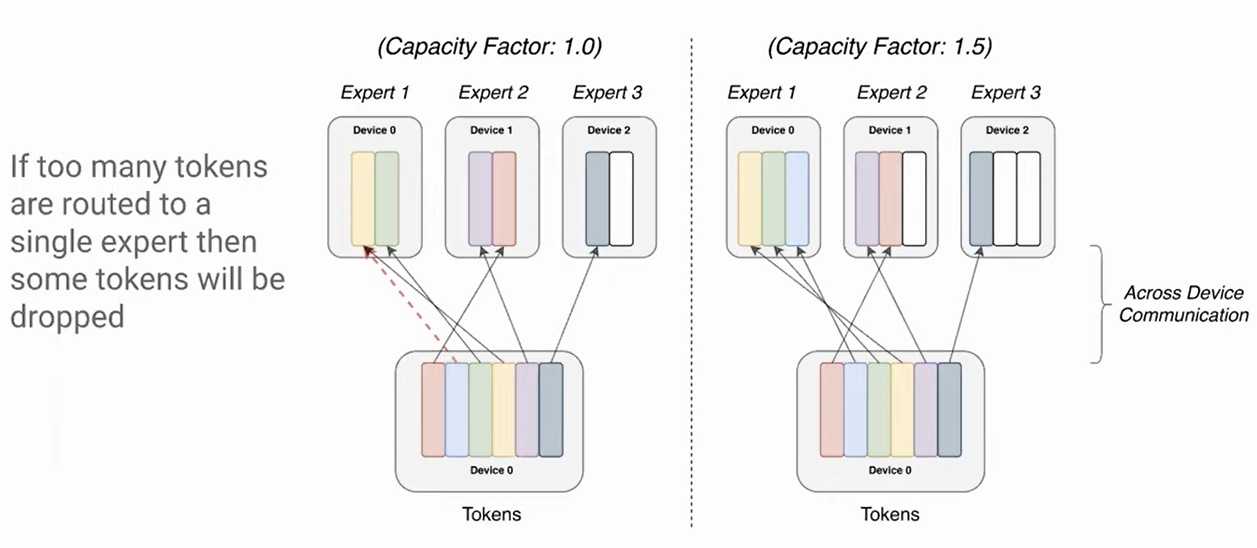
To prevent unstable performance, and CUDA OOM problems, most token choice MoE models implement an expert capacity – a static maximum number of tokens per expert. This is an adjustable hyperparameter that can be changed at any given point of time – at init, at any step, at fine-tuning, and even after training just for inference.
Capacity Factor
In practice, the expert capacity ($EC$) is defined by a related hyperparameter, the capacity factor ($CF$):
$$ EC = round(CF * k * BS_{tokens} / E) $$
where top-$k$ experts (of which there are $E$) are selected per token. When $C<1$, some tokens will always be dropped. When $C>1$, a slack capacity is added, and the frequency of dropped tokens is reduced.
In practice, certain inputs will rely on some experts more than others, and because allocating $C$ infinitely high is infeasible, some tokens will have to be dropped. When the number of tokens routed to an expert exceeds its CF, some tokens will simply be unprocessed by the MoE layer:
Token dropping in Switch Transformers ($k=1$). Pretend there are double the number of arrows and columns in the experts for $k=2$.
Info
If this is unintuitive to you (where does the token go?), remember that transformer layers do an add&norm after each FFN/Attn layer with the previous input, so “dropping” just makes the current layer a null-op for the dropped token:
Sidenote: I think unprocessed is a better term than dropped for this same reason.
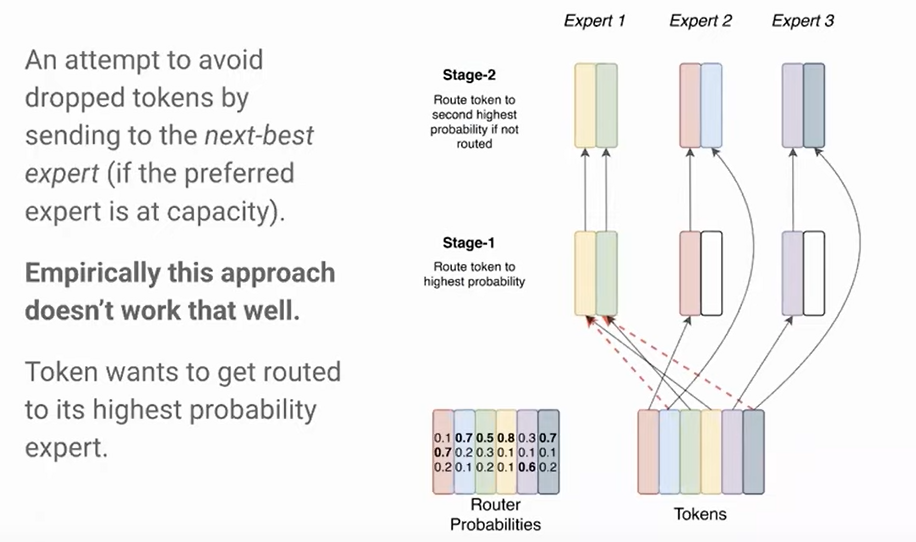
Why not route to the k-th most likely expert?
Instead of leaving tokens unprocessed, couldn’t we at least try to process them by sending them to the 2nd, 3rd, nth most likely expert, as determined by the router?
This idea is known as No Token Left Behind in the literature, and well – it doesn’t work.
Interestingly, actually, this approach didn’t empirically improve model performance. If anything, it actually kind of hurt it. And we thought that was actually very interesting.
And I think the intuition is that once the model learns it wants to send a token to one expert, it really wants to have that computation applied to it. And just applying some other computation doesn’t have, at all, the same property, along with it, actually, maybe being potentially detrimental.
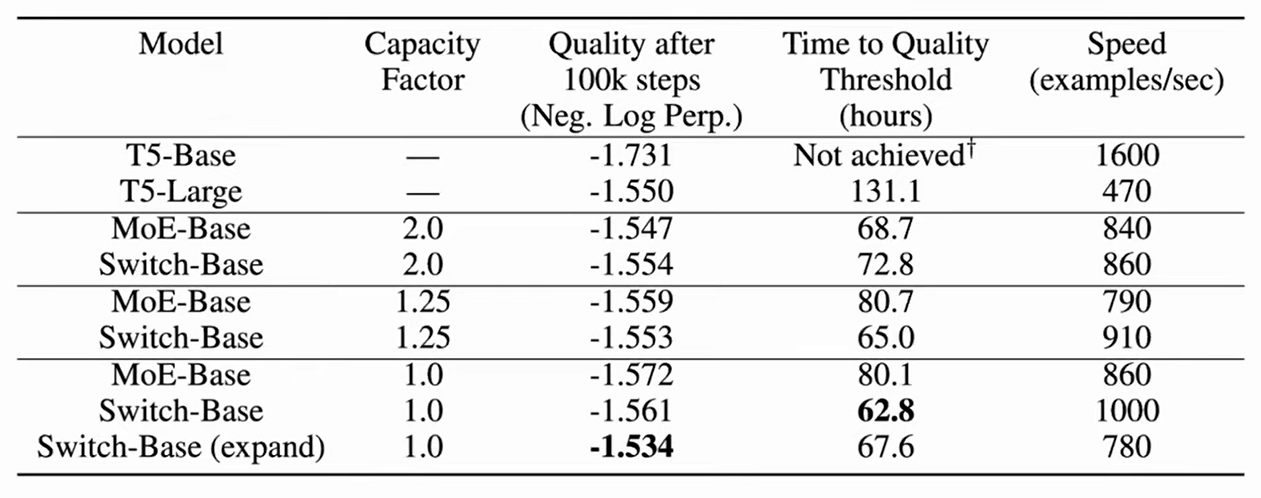
MoE Transformers don’t actually need need to process all tokens to work; having a fairly low CF with a substantial amount of token dropping is okay (and also better for less comm + vram):
In Switch Transformers, NLL is slightly worse on $CF=1.00$ than on $CF=1.25$, but it trains/infers much faster. We can assume the same for OpenAI’s models – allowing some tokens to be dropped during inference is an efficient inference optimization that they don’t have good reasons to fix.
What was the point of this article, again?
Oh, right.
Let’s say I submit two calls to GPT-4:
1
2
3
4
5
prompt='some weird prompt that tends to trigger close to random text'defGPT4(s:str)->str:...# some import openai stuffs1=GPT4(prompt)# prompt1s2=GPT4(prompt)# prompt2asserts1==s2
And I get an assertion error. What happened? Well,
OpenAI’s servers get a lot of user inputs. (Surprising, I know)
They get so many inputs, that they tend to do batching.
prompt1 and prompt2 may be the same sequences, but they don’t end up in the same batch.
As a toy example: batch1 = ["hello", prompt], batch2 = [prompt, "world"]
When a batch is processed by GPT-4, Expert Capacity is used to limit the tokens per expert from all sequences in the batch.
Your tokens have the same $g_x$ in both calls. Other sequences in the batch don’t. Some of your tokens will get dropped in some calls, but not in others.
This changes the final output of the model.
That’s it.
Conclusion
Based on a literature review + leaked information, GPT-4 uses a top-2 Token Choice router.
Token Choice experts have an Expert Capacity that is often exceeded by the number of tokens routed to it within a batch.
Since the same sequence will appear in different batches, different tokens are dropped per API call, causing randomness in what is otherwise a deterministic model.
OpenAI will not immediately fix this – tokens being dropped are generally good for the performance of MoE models