With the raw data in tow, we can construct a proper TTS Dataset with the use of a few Python scripts.
I currently have:
named audio files (AudioClip/)
dialogue lines with IDs (dialog.json)
IDs that are linked to the names of audio files from (1) (VoiceOverClipsLibrary.json)
I want to squash (1) and (2) together – to create dialog lines linked to audio files – and we need to use (3) to get there.
Preprocessing
My idea was simple:
Each line of dialog from dialog.json has an articyID.
Each articyID is linked to an assetName
Each assetName represents a unique .wav file
Run through steps 1-3 to obtain (dialog, wav_file) pairs.
Or at least, it was supposed to be simple. In reality, each and every one of these steps were assumptions – expected conditions that weren’t strictly followed by the raw data I had obtained in the first post.
Here’s what went wrong:
Useless dialogueEntries
Each DialogueEntry in dialog.json contained an articyID, which was great. What was less great was the presence of useless/meta dialogue entries like this:
So, instead of looping through every dialogue entry in the game, I threw every entry into a pandas dataframe and ran articyID queries on that:
1
2
3
4
5
6
7
8
9
withopen(JSON_DIALOG)asf:loaded=json.load(f)df_actors_init=pd.json_normalize(loaded,record_path=['actors'])df_actors=pd.concat([df_actors_init,df_actors_init.pop('fields').apply(iterate)],axis=1)df_convos_init=pd.json_normalize(loaded,record_path=['conversations','dialogueEntries'])df_convos=pd.concat([df_convos_init,df_convos_init.pop('fields').apply(iterate)],axis=1)# To access a dialogueEntry with a given `ArticyID`,# access `df_convos[df_convos["Articy Id"] == ArticyID]`
This was a somewhat inefficient solution and I am not very proud of it. More on this later, in the final script.
One-to-many mapping: ArticyID –> AssetName
Problem: in VoiceOverClipsLibrary.json, some clipInformation[] entries contain alternativeVoiceClips[]. Example:
The full object has only 1 articyID, but many AssetNames. And all of these AssetNames exist as .wav files, and correspond to their own separate dialogue lines:
So, that’s not great. I have to create additional code to handle this edge case.
404 not found: AssetName -/-> .wav file
Some AssetNames pointed to .wav files that simply didn’t exist.
1
2
3
4
5
WARNING: Unable to find .wav file for: 'Titus Hardie-WHIRLING F1 TITUS HARDIE barks-2'
WARNING: Unable to find .wav file for: 'Titus Hardie-WHIRLING F1 TITUS HARDIE barks-3'
... (<1000 lines omitted) ...
WARNING: Unable to find .wav file for: 'Echo Maker-APT ECHO MAKER barks-11'
WARNING: Unable to find .wav file for: 'Echo Maker-APT ECHO MAKER barks-12'
The vast majority of these were labelled as barks, which from what I gather refers to this. Generally speaking, they aren’t actual voice lines and it doesn’t hurt the dataset to simply ignore their presence (or lackthereof).
One-to-many mapping: AssetName –> DialogueEntry
A small number of clipInformation[] entries contained duplicate AssetNames, despite having different articyIDs:
These appear mostly linked to extra dialogue lines added from The Final Cut, and are distinguished by the presence of a fixed- prefix in their PathToCLipInProject:
1
2
3
4
5
6
7
8
{"AssetName":"Kim Kitsuragi-WHIRLING KIM MAIN-55","ArticyID":"0x0100000400008D23","AssetBundle":"whirling_kim-kitsuragi","PathToClipInProject":"Assets\\Sounds/Dialogue/VOImports\\whirling\\kim kitsuragi\\fixed-Kim Kitsuragi-WHIRLING KIM MAIN-55.wav","DoesNotNeedVO":false,"alternativeVoiceClips":[]},
So I implemented extra corner case code for this too.
1
2
3
4
5
6
7
defparseVoiceOver(vo):ID,AN,PATH=vo['ArticyID'],vo['AssetName'],vo['PathToClipInProject']expected_fname=PATH.split('\\').pop()ifexpected_fname[:-4]!=AN:# INACCURATE AN DETECTEDAN=expected_fname[:-4]assertAN[:6]=='fixed-'# this is a very specific kind of file....
404 not found: articyID -/-> DialogueEntry
After fixing all of the above, and making my first attempt to squash all the data, I noticed there were also a few unused (either that or my code was incorrect) .wav files detected:
Buildingfinalcsv...:0%||1/45545[00:00<2:38:26,4.79it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Inland Empire-WHIRLING F2 TEQUILA DOOR-5.wav')]Buildingfinalcsv...:0%|▏|102/45545[00:01<07:45,97.59it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Inland Empire-WHIRLING F2 DREAM 2 INTRO-40.wav')]Buildingfinalcsv...:3%|███▌|1533/45545[00:16<07:32,97.27it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Composure-JAM TOMMY-776.wav')]Buildingfinalcsv...:13%|█████████████▊|5982/45545[01:03<07:05,92.98it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Kortenaer-PLAZA KORTENAER-525.wav')]Buildingfinalcsv...:23%|████████████████████████|10519/45545[01:53<06:26,90.60it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Garte, the Cafeteria Manager-WHIRLING F1 GARTE MAIN-120.wav')]Buildingfinalcsv...:49%|███████████████████████████████████████████████████|22388/45545[04:11<04:40,82.59it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM HUMANITARIAN AID-482.wav')]Buildingfinalcsv...:49%|███████████████████████████████████████████████████▍|22505/45545[04:12<04:35,83.49it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM HUMANITARIAN AID-479.wav')]Buildingfinalcsv...:49%|███████████████████████████████████████████████████▍|22532/45545[04:13<04:35,83.45it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM faln sneakers on a pedestal of speakers-88.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM faln sneakers on a pedestal of speakers-94.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM faln sneakers on a pedestal of speakers-99.wav')]Buildingfinalcsv...:50%|███████████████████████████████████████████████████▍|22550/45545[04:13<04:29,85.40it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of clothes-64.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of clothes-67.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of clothes-74.wav')]Buildingfinalcsv...:50%|███████████████████████████████████████████████████▌|22568/45545[04:13<04:26,86.27it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of sun glasses-77.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of sun glasses-83.wav')]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Siileng-JAM box of sun glasses-87.wav')]Buildingfinalcsv...:57%|███████████████████████████████████████████████████████████|25844/45545[04:53<04:07,79.57it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Kim Kitsuragi-WHIRLING F1 GARTE MAIN-553.wav')]Buildingfinalcsv...:62%|████████████████████████████████████████████████████████████████▎|28138/45545[05:22<03:45,77.19it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Kim Kitsuragi-VILLAGE POSSE 2-74.wav')]Buildingfinalcsv...:82%|█████████████████████████████████████████████████████████████████████████████████████▋|37550/45545[07:25<01:45,75.45it/s]WARNING:unusedaudioclip(s)[PosixPath('AudioClip/Kim Kitsuragi-WHIRLING KIM MAIN-981.wav')]Buildingfinalcsv...:100%|████████████████████████████████████████████████████████████████████████████████████████████████████████|45545/45545[09:16<00:00,81.81it/s
Considering how few of these there were, I deliberately chose to move on instead of investigating further.
Final result
After accounting for all of those intricacies, I end up with this final script:
#!/usr/bin/python3importosimportjsonimportpandasaspdfrompathlibimportPathfromtqdmimporttqdm# this is for df.append()importwarningswarnings.simplefilter(action='ignore',category=FutureWarning)### filepathsos.chdir('../0_original_data')JSON_DIALOG='./dialog.json'JSON_VOCLIPS='./VoiceOverClipsLibrary.json'WAV_AUDIOCLIPS_FOLDER=Path('./AudioClip')### List /AudioClip/ folderaudio_assets={wav_file.stem:wav_fileforwav_fileinWAV_AUDIOCLIPS_FOLDER.iterdir()}print('loaded audio clips folder')### Load VoiceOverClipsLibrary into clips{}clips={}defaasset(k):v=audio_assets.get(k,None)ifvisNone:print(f"WARNING: Missing '{k}'")defparseVoiceOver(vo):ID,AN,PATH=vo['ArticyID'],vo['AssetName'],vo['PathToClipInProject']expected_fname=PATH.split('\\').pop()ifexpected_fname[:-4]!=AN:# INACCURATE AN DETECTEDAN=expected_fname[:-4]assertAN[:6]=='fixed-'# this is a very specific kind of file.path=audio_assets.get(AN,None)ifpathisNone:returnprint(f"WARNING: Unable to find .wav file for: '{AN}'")clips[ID]=[path]foraltinsorted(vo['alternativeVoiceClips'],key=lambdaalt:alt['AlternativeID']):#assert alt['AlternativeClipPath'].split('\\').pop()[:-4] == alt['AlternativeAssetName']# Alt assets do not appear to have the "fixed-" problem.clips[ID].append(audio_assets[alt['AlternativeAssetName']])withopen(JSON_VOCLIPS)asf:loaded=json.load(f)df_vo=pd.json_normalize(loaded,record_path=['clipInformations'])filtered=df_vo.filter(['AssetName','ArticyID','alternativeVoiceClips','PathToClipInProject'])filtered.apply(parseVoiceOver,axis=1)print('parsed VoiceOverClipsLibrary')### Load dialog.json into DataFramesdefiterate(values):returnpd.Series({x["title"]:x["value"]forxinvalues})withopen(JSON_DIALOG)asf:loaded=json.load(f)df_actors_init=pd.json_normalize(loaded,record_path=['actors'])df_actors=pd.concat([df_actors_init,df_actors_init.pop('fields').apply(iterate)],axis=1)df_convos_init=pd.json_normalize(loaded,record_path=['conversations','dialogueEntries'])df_convos=pd.concat([df_convos_init,df_convos_init.pop('fields').apply(iterate)],axis=1)print('Read huge dialog json file')### Create processed csv filedf_final=pd.DataFrame(columns=['fname','acticyID','alternativeIdx','text','actorID','actorName'])# shape of the output csvforaID,clip_lsintqdm(clips.items(),desc='Building final csv...'):dialogueEntries=df_convos[df_convos["Articy Id"]==aID]ifdialogueEntries.shape[0]==0:print(f'WARNING: unused audio clip(s) {clip_ls}')continueassertdialogueEntries.shape[0]==1# make sure there's only 1 entrydialogueEntry=dialogueEntries.iloc[0]# get the entryactor=df_actors[df_actors.id==int(dialogueEntry.Actor)].iloc[0]fori,pathinenumerate(clip_ls):text=dialogueEntry['Alternate%d'%i]ifielsedialogueEntry['Dialogue Text']df_final=df_final.append({'fname':path.name,'acticyID':aID,'alternativeIdx':i,'text':text,'actorID':actor.id,'actorName':actor.Name,},ignore_index=True)df_final.to_csv(r'AudioClipMetadata.csv',index=False)
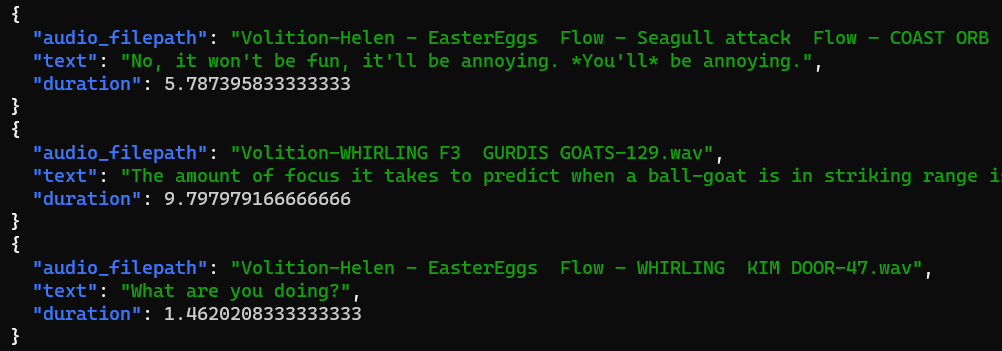
The script is single-threaded, because I don’t know how to properly operate pandas. After about fifteen minutes of waiting, I end up with a .csv file that looks like this:
Audio files, lines, and actor names. Great.
Packaging
Now, there are a few problems with the audio transcript as-is:
Unaccepted punctuation. *asterisks* for emphasis, dashes (--) and ellipses (...) for pauses, quotation marks ("") – these are all readable by humans, but poorly handled by the models I’ll be using.
Fantasy words. Oranje, Revachol, Kineema, radiocomputer, Reál, Isola… Some people have the volition to sift through entire datasets, manually assigning the right pronunciations to each word. I am not one of those people.
Lines that just shouldn’t exist in any audio dataset. For example:
Half-Finished Paperwork: KK57-0803-0815 (THE HANGED MAN)
Pale Latitude Compressor: “236189281… If you’re looking for a deal on mattresses… SUHSUHSUHSPEEDFRRRR… 23567… 32971047302819… Oh Rosaline, oh Rosaline…”
But I’m going to ignore these problems for now. We have close to 50k lines of speech, and given about half of those are by the Narrator, that’s >20k lines of training data. I assume that’s enough to get a passable first model, even with problems in the dataset.
So, ignoring those issues for the future I want to format my raw data for an AI blackbox to eat. Which AI? From what little I know, Tacotron 2 is one of the simplest and cheapest models to train. Starting with it sounds like a good idea. Let’s read the tutorial:
Well, this is quite nice. I don’t really know what a phoneme is (yet), and much of the audio I have is significantly longer than 10 seconds, but the other 4 bullet points seem to be OK.
The data format shown above is also delightfully simplistic. The main problem for us is that it requires a "duration" field, which our current raw data does not declare. This isn’t much of a problem; it’s trivial to extract the info from each .wav file:
Here, I’ve made the outlines of a script to create each expected json line with multithreading. I leave an exit() in the main loop so that I can test that the script approximately works without parsing everything yet:
1
2
$python3duration.py{"audio_filepath":"Inland Empire-BOOKSTORE BIOGRAPHIES-29.wav","text":"You feel like you should get this one. Definitely. It's *important* somehow. There is something personal inside...","duration":7.793041666666666}
Format looks good. But I’m not looking to use all of the voices here; just the voices of the narrator. I need to figure out which voice actors are narrated and which aren’t.
Step 1 is to extract a list of actors. I use disco-courier to export actors.json:
Well, this is clearly useless. isNPC covers narrated actors like Perceptionand other voice actors like Kim Kitsuragi, while isPlayer covers absolutely nothing of value.
Reading actors.json further, I realise that there are actors like Ceiling Fan or "Smallest Church in Saint-Saëns" that are actually voiced by the main Narrator too:
1
2
3
4
5
6
7
8
9
10
$ jq .actors[].name src/data/json/actors/actors.json | tail -100
"Door, Basement Apartment""The Great Doorgunner Megamix""Coffee Table""A Note from the Fridge""Shimmering Wall of Vices""Photo of Tattoos""\"Smallest Church in Saint-Saëns\"""Karaoke Stand""A Folded Library Card"
So, disco-courier is ineffective here, and we have no idea which actorID corresponds to the Narrator of the game, so we’ll need to…
… *deep sigh* …
…manually label the data.
Filtering for voice actors
The voice actors can be split into 5 categories for our purposes:
NPCs (like Kim Kitsuragi)
Narrator (obviously)
Not sure (I don’t have an encyclopedic knowledge of the game; I’ll ignore a few actors for now and check again later)
404 Not Found. Interestingly, several voice actors listed in actors.json do not actually have any voice lines.
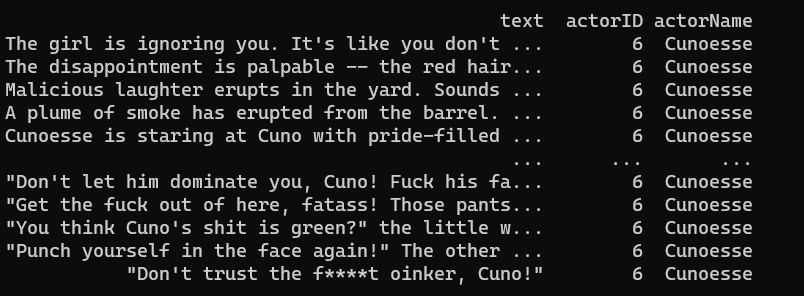
Mixed voices. Many of the voice lines labelled to be by an NPC are actually narrated. Consider these lines, labelled to be by Cunoesse:The top 5 are narrated; the bottom five aren’t. The full solution to this is not as simple as, “look for quotation marks”, either. Scare/rhetorical quotes are a thing.
I started work by editing the .json file in a text editor, but quickly realised it was ridiculously slow. Instead, I created a buggy script to minimise the time delay between each label:
importpandasaspdfromprompt_toolkitimportpromptfromprompt_toolkit.key_bindingimportKeyBindingsfromtermcolorimportcprintfromjsonimportload,dump,dumpswithopen('./actors.json')asf:actors=load(f)['actors']df=pd.read_csv('./AudioClipMetadata.csv')res=[]defhandle(opt:str):print()ifnotopt:print(dumps(res))elifopt=='back':res.pop()eliflen(actors)>len(res):res.append({**actors[len(res)],'narratorType':opt})else:print('press q bro')#while1:iflen(actors)==len(res):breaka=actors[len(res)]cprint(a['name'],'magenta',None,['bold','underline'])desc=a.get('longDescription','')ifdesc:cprint(desc,'yellow')else:cprint('No description','grey')#lines=df[df['actorID']==a['actorId']]iflines.shape[0]:print(lines)breakelse:cprint('No lines found for this Actor. Skipping...','grey')res.append({**actors[len(res)],'narratorType':'Absent'})print('> ',end='')bindings=KeyBindings()defbind(c:str,out:str):@bindings.add(c)def_(e):handle(out)bind('enter','')bind('b','back')bind('1','NPC')bind('2','Narrator')bind('3','Unknown')bind('4','Mixed')@bindings.add('q')deffinish(e):withopen('actors_by_narrator.json','w')asf:dump(res,f)exit()prompt("Press enter to begin: ",key_bindings=bindings)
This script breaks extremely often, but it was enough for me to create the labelled data within a few hours:
1
2
3
4
5
6
7
8
9
10
11
$ jq .[].narratorType actors_by_narrator.json | head
"Absent""Absent""Absent""Absent""NPC""Mixed""Mixed""NPC""NPC""NPC"
The First Dataset
I finished the script from earlier to create the json file:
importcsvimportwaveimportcontextlibimportpandasaspdfromshutilimportcopyfromtypingimportListfromjsonimportdumps,loadfrommultiprocessingimportPoolAUDIO_DIR='./AudioClip/'AUDIO_DIR_NEW='./AudioClip_Narrator/'withopen('./actors_by_narrator.json')asf:df_actor=pd.json_normalize(load(f))# https://stackoverflow.com/a/7833963defduration(fname:str)->float:withcontextlib.closing(wave.open(fname,'r'))asf:frames=f.getnframes()rate=f.getframerate()returnframes/float(rate)# 2.2565208333333335 == duration('./AudioClip/ANTI OBJECT TASK FORCE_TITLE.wav'))defcsvToJson(fname:str,text:str)->str:t=duration(AUDIO_DIR+fname)returndumps({'audio_filepath':fname,'text':text,'duration':t})# ['fname', 'acticyID', 'alternativeIdx', 'text', 'actorID', 'actorName']defconsider(line:List[str]):fname,text,actorID=line[0],line[3],line[4]actor=df_actor.loc[int(actorID)-1]assertactor.actorId==int(actorID)ifactor.narratorType=='Narrator':copy(AUDIO_DIR+fname,AUDIO_DIR_NEW+fname)# very slow operation.returncsvToJson(fname,text)CORES=8withopen('./AudioClipMetadata.csv')ascsvfile,Pool(CORES)aspool,open('./AudioClips_Narrator.json','w')asjson_file:reader=csv.reader(csvfile)next(reader)# ignore headerforjson_lineinpool.imap(consider,reader,1<<8):ifjson_line:json_file.write(json_line+'\n')# this isn't pooled, but this is ok since consider() is much slower.
Looks good:But we’re supposed to split this into test/train data. Let’s copy a stackoverflow solution again:
# https://stackoverflow.com/a/48347284importrandomdefsplit_file(file,out1,out2,percentage=0.75,isShuffle=True,seed=123):"""Splits a file in 2 given the `percentage` to go in the large file."""random.seed(seed)withopen(file,'r',encoding="utf-8")asfin, \
open(out1,'w')asfoutBig, \
open(out2,'w')asfoutSmall:nLines=sum(1forlineinfin)# if didn't count you could only approximate the percentagefin.seek(0)nTrain=int(nLines*percentage)nValid=nLines-nTraini=0forlineinfin:r=random.random()ifisShuffleelse0# so that always evaluated to true when not isShuffleif(i<nTrainandr<percentage):# or (nLines - i > nValid): # <-- error in the SO solution.foutBig.write(line)i+=1else:foutSmall.write(line)split_file('./AudioClips_Narrator.json','./AudioClips_Narrator_train.json','./AudioClips_Narrator_val.json')
I can verify that this doesn’t accidentally delete any of the lines:
1
2
$ cat AudioClips_Narrator_* | sort | diff - <(sort AudioClips_Narrator.json) -s
Files - and /dev/fd/63 are identical
And now we just need to pack the data:
1
2
3
4
$ # this step takes a few minutes$ tar zcf disco_dataset_NARRATOR.tar.gz AudioClip_Narrator/ AudioClips_Narrator_*
$ du disco_dataset_NARRATOR.tar.gz -h # check filesize7.1G disco_dataset_NARRATOR.tar.gz
7GB is big, but not too big. Google Drive provides 15GB of space for free, so I’m good to go for Colab training.
 So, that’s not great. I have to create additional code to handle this edge case.
So, that’s not great. I have to create additional code to handle this edge case. These appear mostly linked to extra dialogue lines added from The Final Cut, and are distinguished by the presence of a
These appear mostly linked to extra dialogue lines added from The Final Cut, and are distinguished by the presence of a  Audio files, lines, and actor names. Great.
Audio files, lines, and actor names. Great.