Paper summary: LLaMA-like 7B/67B pretrain (Base) + SFT&DPO (Chat). 2T tokens with strong CN/EN mix, >1mil SFT examples. Well-executed exploration of scaling laws. Good details about evals and safety. Not much described about their actual data.
Dataset
They note that CC deduplication removes a lot more content iff done across dumps rather than within individual dumps:
For the unaware reader: CC archives are split by month (approximately); see this index. So it is pretty unsurprising that there are a lot of duplicate entries across time.
I wonder if a substantial number of pretraining runs in the wild got fucked over by this implicit data-duplication, though.
Arch
100k BPE tokenizer that prevents newlines/punctuation/CJK symbols from merging with one another (I don’t know how to implement that and should probably find out), and also keeps digits as singular unmerged tokens. They train the tokenizer on 24GB of text (are there scaling laws for this?) and add 15 special tokens and pad to 102400.
All models use LLaMA/Noam arch + 4k ctxlen, and AdamW $\beta_1=0.9, \beta_2=0.95$ w/ 0.1 weight decay & grad clip 1.0
7B: L=30 D=4096 H=32 Hkv=32bs=2304 lr=4.2e-4
67B: L=95 D=8192 H=64 Hkv=8bs=4608 lr=3.2e-4
They init both models with stddev 0.006. They do not specify what distribution this is, but in several pretraining toolkits this usually refers to $\mathcal{N}(0, \sigma^2)$.
They state that L=30/95 was picked specifically to “facilitate model pipeline partitioning to optimize training and inference.” That is a bit weird to me because $95 = 19*5$. A pipeline hardcoded for 5 nodes only? If you include the embedding layer, then $L=30+1$ would also be prime. Confusing.
For the LR scheduler, they use some bespoke multi-step (step as in cliff-like) thing, which should be implemented as
Motivation is similar to WSD and etc: training can be extended infinitely from the 80% mark as the LR will not have gone down yet.
Infra
Internal HAI-LLM harness does basic 1F1B-PP/TP/SP + ZeRO + flash-attn + xentropy + other obvious stuff. They accumulate grads in fp32.
Their checkpointing is decent: async checkpointing every 5 minutes + resumption to different parallelism configs.
They use VLLM for inference.
Scaling experiments
Instead of using the traditional $C=6ND$, they do $C=MD$, where $M = 72L\cdot D^2 + 12L\cdot D\cdot l_{seq}$ is the non-embedding FLOPs per token. This accounts for SDPA flops and ignores embedding layer.
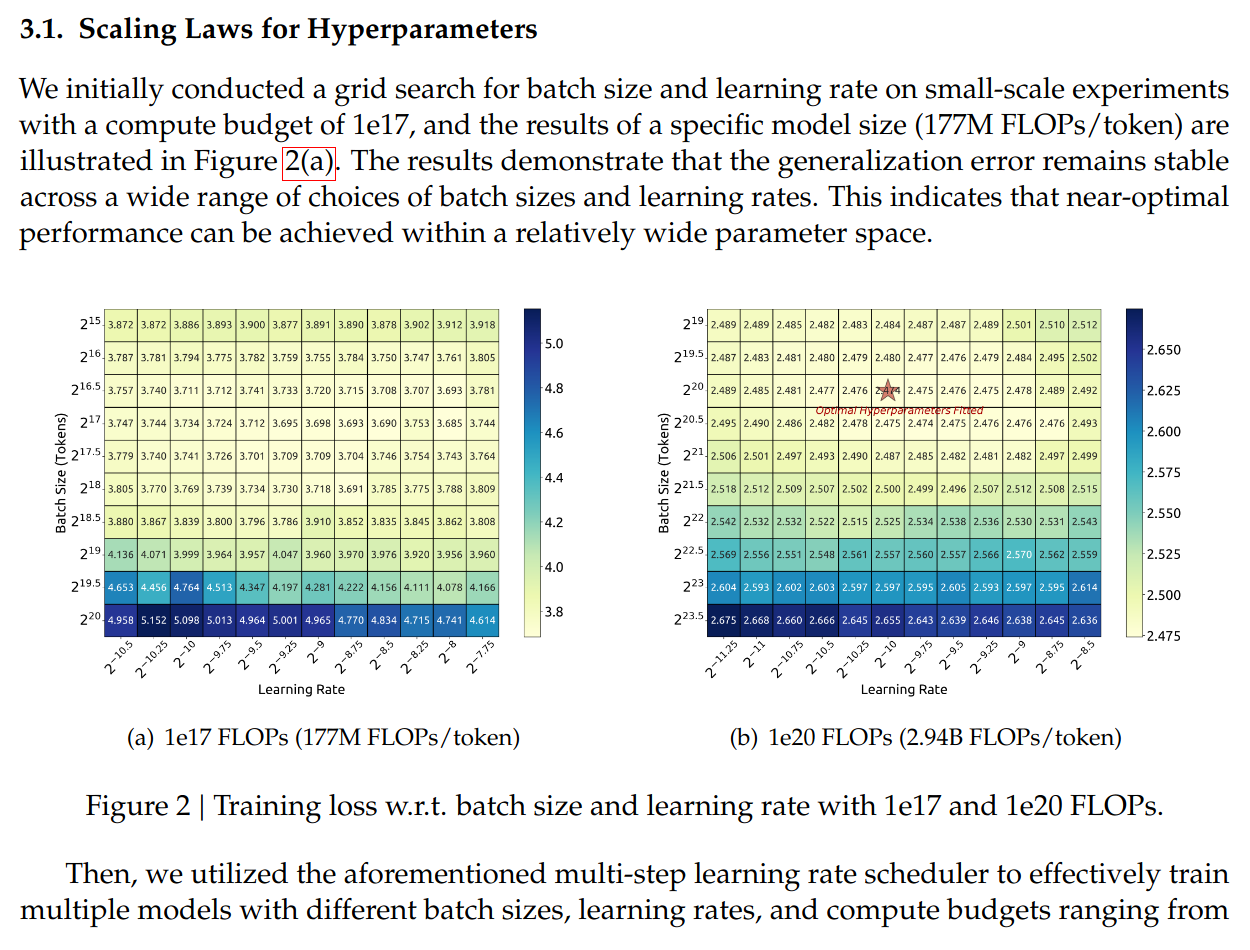
So they do some isoflops scaling experiments on [batch size, lr, compute budget $C$]:
a grid search for optimal BS/LR @ 1e17 / 1e20 FLOPs:
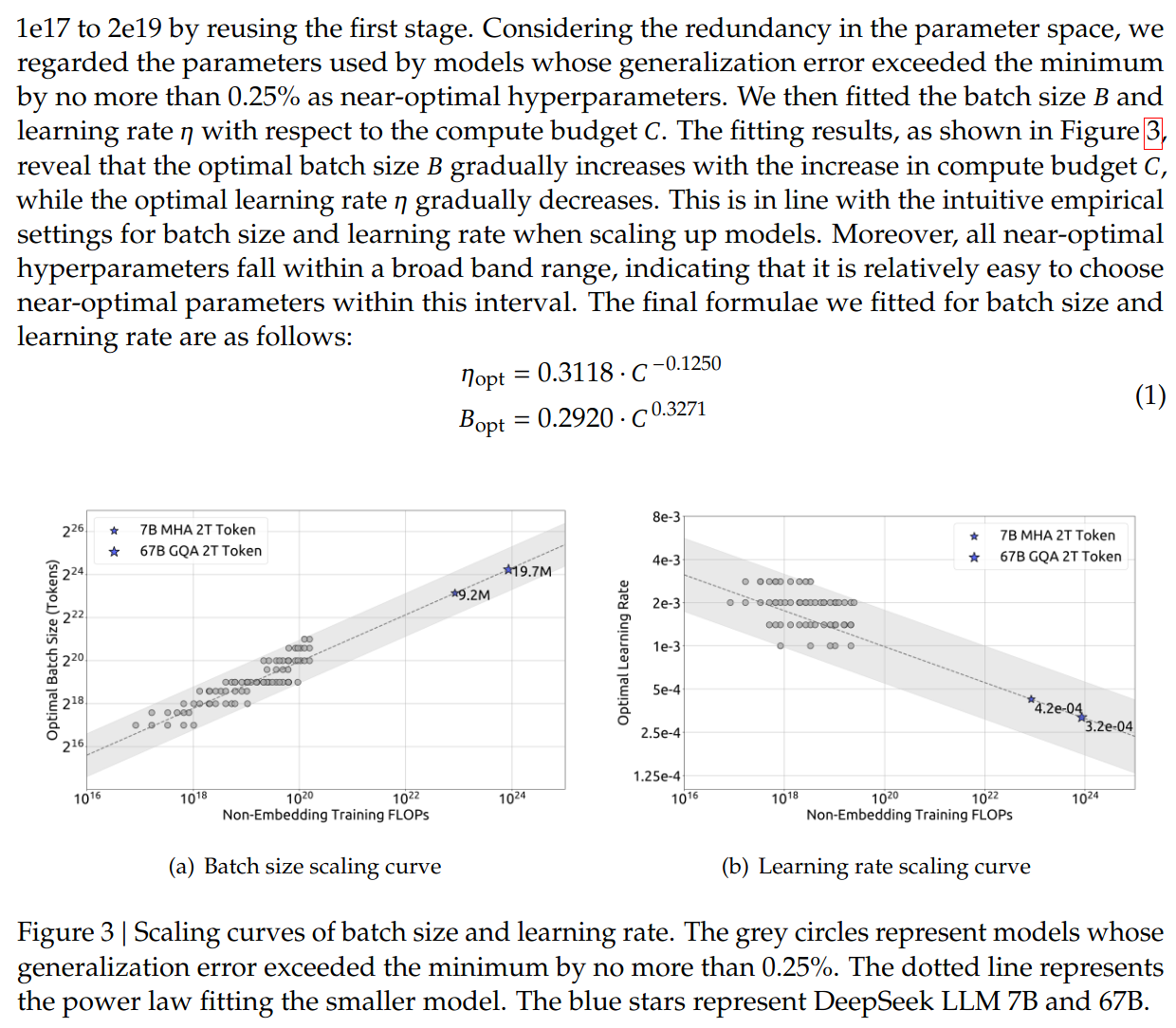
Continuing from the 1e17 FLOPs run, they explore many continued training experiments to $C \in [1e17, 2e19]$, varying BS/LR again, to plot a graph of all the runs that have a final loss within 0.25% of the minimum. Conclusions in the blurb:
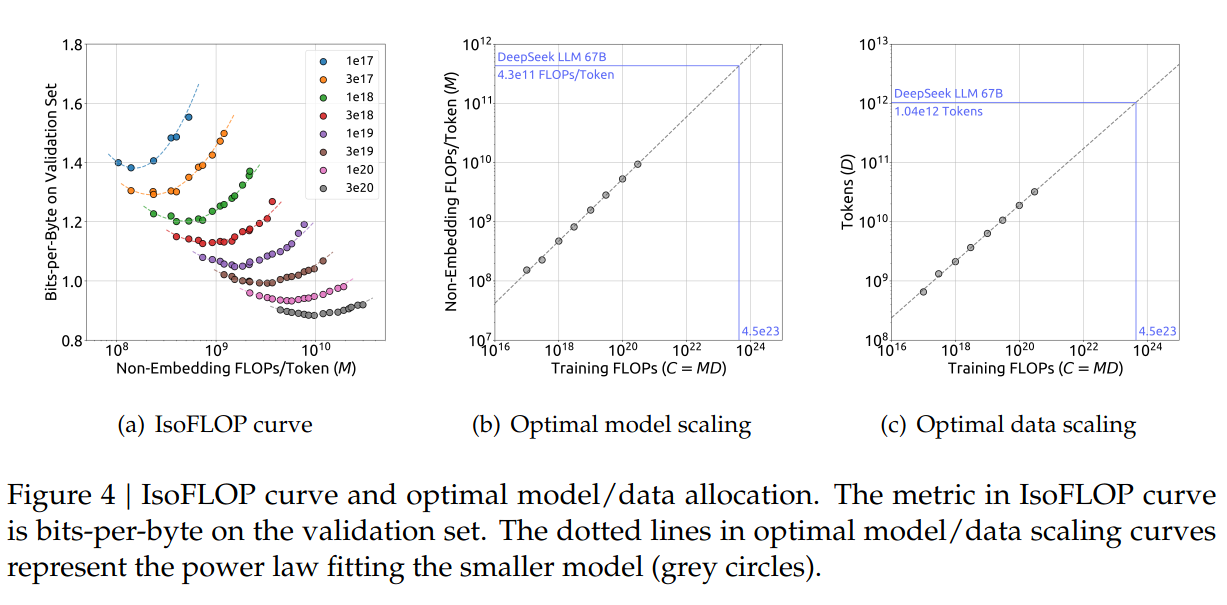
Using the obtained optimal BS / LRs, they do chinchilla-like experiments to find $argmin\ L(N,D)$ for varying $C=MD$:Note that $L$ is defined as bits-per-byte (rather than CELoss) on a validation set of 100M tokens.
For their dataset, $M_{opt} = 0.1715 * C^{0.5243}$ and $D_{opt} = 5.8316 * C^{0.4757}$.
In the appendix, they note that Chinchilla’s original $C=6PD$ law leads to performance overestimation/underestimation, depending whether embedding params are included in $P$ or not.
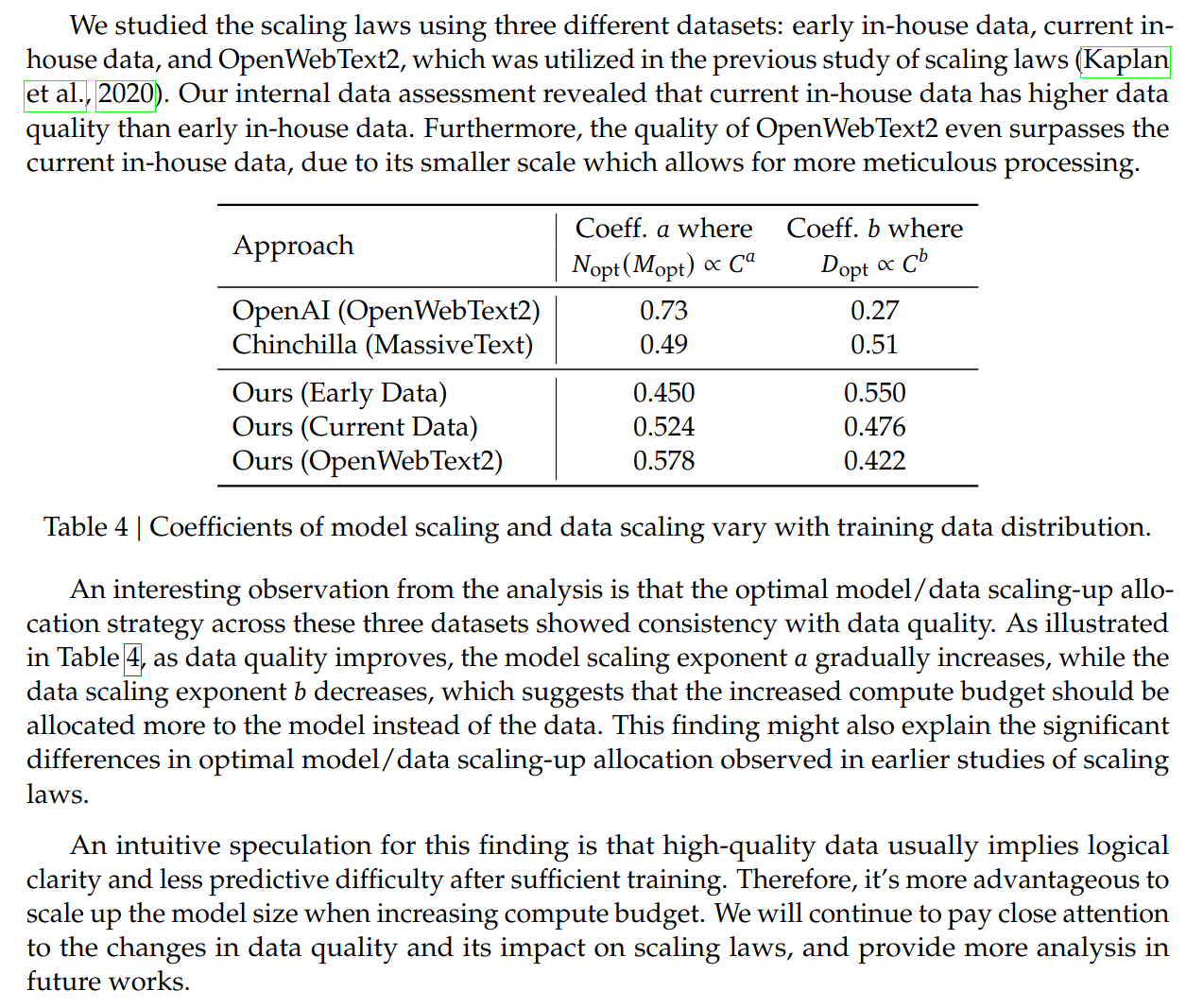
They find that better data increases the ideal value of $M$ for fixed $C$.I have contentions with their intuitions as described above, but the empirical results are important.
Note that:
they never mention the param initialisation used for any of their experiments.
Presumably, there was no mUP-like initialisation scaling involved, and they used $\mathcal{N}(0, 0.006^2)$ for everything. Or maybe they used default torch init?
they never state how they determine which of $L,D$ to vary (or how much to vary) when $M$ is changed. Kaplan 2020 implies it shouldn’t matter too much whether they varied L or D more, though.
the equation for $M$ only makes sense if you have no attention mask && you do MHA && have a constant 8/3 FFN ratio w/ GLU (or a FFN ratio of 4 for a non-GLU model) && you ignore lmhead FLOPs.
If you parameterize $R_{kv} = \frac{\text{k or v heads}}{\text{q heads}}$ and $R_{\text{ffn}} = 4$, you should instead have
In any case, their predictions hold up to 67B scale, so I don’t have a good empirical reason to complain.
Alignment
1.5 mil CN+EN instructions. 20% of those are for safety refusals; of the remaining 80% they have around $\frac{2}{9}$ code $\frac{4}{9}$ maths $\frac{1}{3}$ language tasks.
They do 4 epoches $lr=10^{-5}$ for 7B and 2 epoches $lr=5*10^{-6}$ for 67B (avoid overfit).
Interestingly, they notice that their SFT model tended to degrade into repetition more often as the quantity of math SFT data increased, allegedly because their math data repeats information to do reasoning. To fix this, they do a 2nd fine-tuning round on their 7B model with only conversational data (and no math/code); this doesn’t negatively affect their HumanEval/GSM8K results.
They do DPO w/ lr 5e-6 and $BS=512$ and warmup cosine scheduler. Dataset is collected prompts –> SFT model generations –> ratings.
Evals
They use an internal eval framework (no details) on MMLU/C-Eval/CMMLU/HellaSwag/PIQA/ARC/OpenBookQA/BBH/TriviaQA/NaturalQuestions/RACE/DROP/C3/WinoGrande/CLUEWSC/Pile/CHID/CCPM/GSM8K/MATH/CMath/HumanEval/MBPP/AGIEval.
For generation-based tasks, they use greedy decoding. They also do BPB evaluation on Pile-test.
Various Notes on Results
They note that their models perform similarly to LLaMA 2 on English benchmarks, despite having much less English data. Their 67B model beats l2-70B more than their 7B model beats l2-67B, possibly implying that dual CN/EN language modelling has a more painful impact for smaller models.
They give arguments for why changes in TriviaQA/MMLU/C-Eval/BBH/NaturalQuestions perf between Base and Chat models are not indicative of “acquisition or loss of knowledge” or “learn[ing] reasoning capabilities” after SFT, but are just learning the correct formatting / zero-shot behaviour.
They note that Base models are naturally better at direct cloze/completion tasks like HellaSwag, and that their Chat model performs much better on math/coding tasks, presumably learned through the SFT data.
Ritualistically, they repeatedly note that their model outperforms ChatGPT 3.5 and is only second to GPT-4 on evals XYZ, because every pretraining org has to say that for some reason.
For open-ended evaluation, they use AlignBench for Chinese, optimising the generation temperature used depending on domain. For English, they use MT-Bench. Both of these involve GPT-4 dogfooding.
On held out evals
They use novel LeetCode weekly contest problems to test the coding capabilities of the model. They say,
The model’s coding capabilities are depicted in the Figure below, where the y-axis represents the pass@1 score on in-domain human evaluation testing, and the x-axis represents the pass@1 score on out-domain LeetCode Weekly Contest problems.
However, this Figure does not actually exist in the paper. Neither does it exist in the Deepseek Coder paper. To the dear reader: Please contact me / leave a comment if you are able to find it.
Anyway: They find that their model outperforms everything other than GPT-4 on LeetCode/Hungarian Exam/IFEval.
Safety
They take safety seriously enough to develop a taxonomy of unsafe topics, ensuring that their model is well-rounded and does not fall to basic jailbreaks/loopholes. They have an “expert team” dedicated to developing a high quality diverse safety test set of 2.4k questions, involving “inducement, role-playing, multi-turn dialogues, preset positions, and etc”, and create a guideline constitution for their safety reviews.
They are better than GPT-4/ChatGPT (…) on Do-Not-Answer by 0.1%. Thankfully, they do not obtain l2-7b-chat’s performance of 99.4%.
On MCQ Evals
DeepSeek discovered that their MCQ-based evals are drastically improved when they add 20M multiple-choice Chinese questions to their alignment dataset:
Heroically, they chose to exclude MC data from their final training runs, as they believe it is merely benchmark-fitting and not representative of true model intelligence.
On instruction data in pre-training
Some labs include SFT data in pre-training to improve benchmarks. DeepSeek tested between:
adding 5M instructions (i.e. ~1M SFT + ~4M MCQ) to the last 10% of pre-training
not adding and then doing 5M SFT later
and found the benchmark results were ~thesame.
Adding instruction data during pre-training is reasonable if the dataset is big enough, but because they only use 1.5M instructions in the end, they don’t.
On sysprompt
On MT Bench, their 7B model is slightly worse (-0.04) with a sysprompt, but their 67B model is substantially better (+0.23) with one.
Other things
DeepSeek 1.0 was released over 6 months ago. In the conclusion, they promised:
Today, it is incredibly impressive to see how they’ve delivered on this vision with DeepSeek-Coder V2.
…
Also, this is the sole and only underlined segment in their entire paper: